Cargar datos de manera masiva en Odoo siempre fue un desafío. No por la complejidad de la tarea, sino por su velocidad. Odoo para las operaciones de carga masiva es desesperadamente lento. Lo más rápido que puede darnos es el método load del que ya hablamos en otras oportunidades.
Ahora vamos a hablar un utilitario poco conocido en la comunidad de Odoo en Argentina (no somos grandes expertos en PostgreSQL, lamentablemente). El comando COPY. El cual permite insertar registros de forma masiva desde un archivo CSV. Por ejemplo, permite cargar en pocos segundos los cientos de miles de registros del padrón de retenciones de ARBA. Aca tenemos un screenshot de ello:
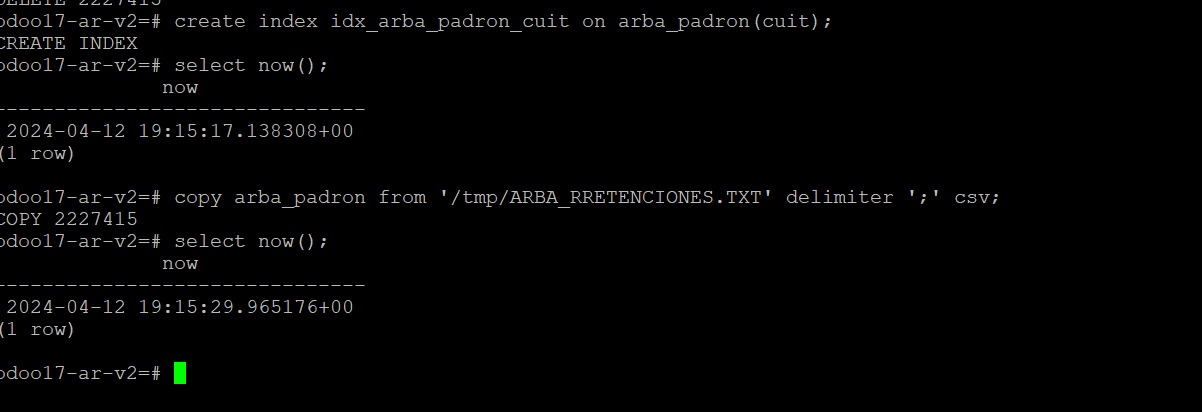
En menos de 20 segundos insertó (actualizando índices) más de dos millones de registros. En un servidor que es de testeo. Como hicimos esta prueba? Primero creamos una tabla donde vamos a almacenar los contenidos del padrón:
CREATE TABLE IF NOT EXISTS ARBA_PADRON (
TIPO_REG CHAR(1),
FECHA CHAR(8),
FECHA_DESDE CHAR(8),
FECHA_HASTA CHAR(8),
CUIT CHAR(11),
DUMMY1 CHAR(1),
DUMMY2 CHAR(1),
PORCENTAJE FLOAT,
DUMMY3 CHAR(2),
DUMMY4 CHAR2(2),
)
Ahora veamos el formato del archivo de retenciones de ARBA
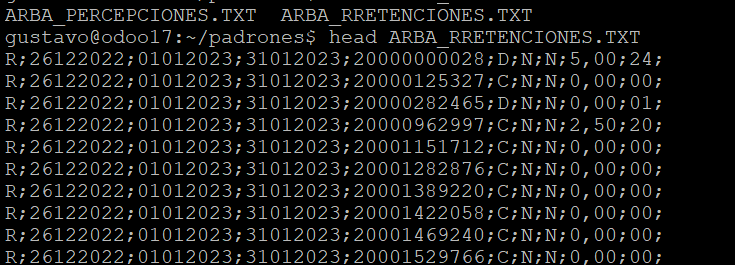
Para luego cargarlo mediante PSQL con el comando COPY:
COPY ARBA_PADRON FROM '/tmp/ARBA_RRETENCIONES.TXT' DELIMITER ';' CSV;
Y se carga el archivo en cuestión de segundos. El archivo de ARBA debe modificarse, cambiando el separador de coma por el punto (al menos en la configuración de mi PostgreSQL). Para ello ejecuto el comando sed
sed -i 's/,/./g' ARBA_RRETENCIONES.TXT
La verdad que las facilidades que encontramos en Linux y en PostgreSQL pueden llegar a ser maravillosas. Ahora (que es lo que vamos a hacer) es relacionar la base de datos del padrón de ARBA con las operaciones de pago o facturación que requieran percepciones y retenciones.