La velocidad de Odoo esta bien para procesar las transacciones de una PyME pero su ORM no es rápido y eso se nota cuando se deben importar miles de registros. Ahí pasa a ser desesperantemente lento.
Ahora Odoo posee un método (el método load) del que se habla poco que permite importar y actualizar miles de registros en forma rápida (con el ORM, la verdad el porque no hablan de el sigue siendo un misterio para mi). Por ejemplo, probé la creación de 1,000 contactos (modelo res.partner) y la inserción solo tardó 13 segundos. Muy rápido, lo que es increible es que se insertaron utilizando el ORM.
Si vemos la definición del método en el código:
@api.model
def load(self, fields, data):
"""
Attempts to load the data matrix, and returns a list of ids (or
``False`` if there was an error and no id could be generated) and a
list of messages.
The ids are those of the records created and saved (in database), in
the same order they were extracted from the file. They can be passed
directly to :meth:`~read`
:param fields: list of fields to import, at the same index as the corresponding data
:type fields: list(str)
:param data: row-major matrix of data to import
:type data: list(list(str))
:returns: {ids: list(int)|False, messages: [Message][, lastrow: int]}
"""
Como se invoca el método? Este es un ejemplo para crear productos:
fields = ['name','default_code','responsible_id','categ_id']
data = [['Product 1', 'product-1','Admin','All'],['Product 2', 'product-2','Admin','All']
create_ids = self.env['product.template'].load(fields,data)
Como pueden ver, solo tienen que invocar el método con los campos a actualizar/insertar y una lista (de listas) con los datos formateados para su actualización/inserción. La actualización de las columnas del tipo many2one se les puede pasar el external ID (mucho mejor para la actualización). Y se lo hace de la siguiente manera:
fields = ['name','default_code','responsible_id','categ_id/id']
data = [['Product 1', 'product-1','Admin','All'],['Product 2', 'product-2','Admin','product.product_category_consumable']
create_ids = self.env['product.template'].load(fields,data)
Como pueden ver solo se debe modificar la definición del campo many2one (por ejemplo categ_id/id) y los datos mismos. Pero es simple. Solo hay que saber como hacer que cada uno de sus datos en los campos many2one tenga un external ID.
Vale la pena agregar que el método load tiene el gran valor agregado que permite actualizar registros. No es menor el detalle.
Ejemplo de carga de contactos
Veamos un ejemplo en el que contamos con un archivo Excel con 1000 contactos. Este se encuentra en el directorio tmp y tiene la siguiente estructura:
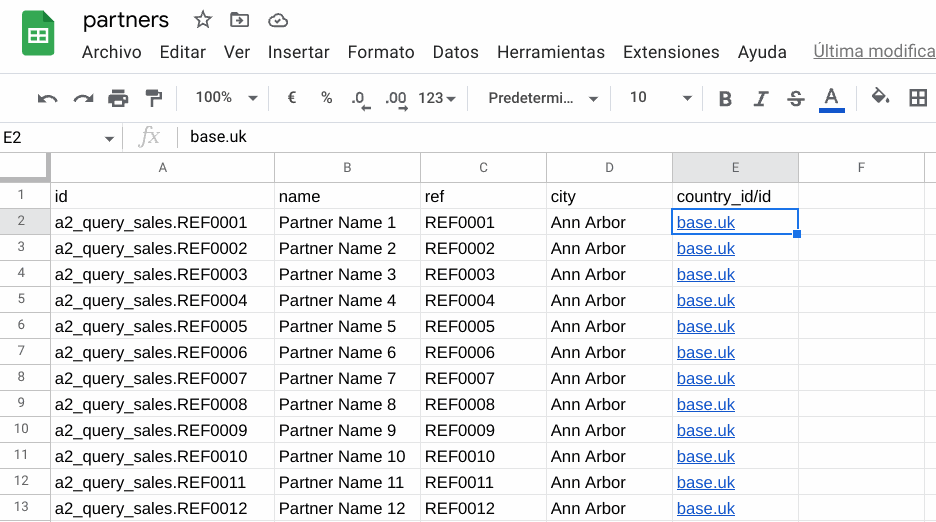
Podemos ver que tenemos varios campos: id (con el external id que le vamos a otorgar al registro que importamos/queremos actualizar), el nombre, la referencia, la ciudad y el pais (campo Many2one, en ese caso se debe proveer el external ID del registro relacionado).
El código que tenemos que utilizar en nuestro módulo de Odoo para insertar/actualizar estos registros es el que se ve a continuación:
fields = ['id','name','ref','city','country_id/id']
data_lines = []
workbook = openpyxl.load_workbook("/tmp/partners.xlsx")
# Define variable para la planilla activa
worksheet = workbook.active
# Itera las filas para leer los contenidos de cada celda
rows = worksheet.rows
for x,row in enumerate(rows):
# Saltea la primer fila porque tiene el nombre de las columnas
if x == 0:
continue
# Lee cada una de las celdas en la fila
data = []
for i,cell in enumerate(row):
# saltea registros con valores vacios
if cell.value == None:
continue
data.append(cell.value)
data_lines.append(data)
res = self.env['res.partner'].load(fields,data_lines)
Pruebenlo, el método load es muy rápido para el insert como para el update (sigo sorprendido porque Odoo no lo promueve más, solo necesita ser mejor documentado). Por ejemplo, otra prueba que hice fue insertar 1,000 contactos con un campo many2one (el país, country_id) se tardó 28 segundos. Actualizando el país de dichos contactos, se tardó solo 32 segundos. Rapidísimo.
El método load al ser invocado devuelve un diccionario con los siguientes elementos: ids (con los IDs de los registros insertados/actualizados), messages (con los mensajes de error que pudieron haber), y nextrow. Como funciona? Por ejemplo queremos actualizar el campo country_id a un valor inexistente en la base de datos. En ese caso por cada registro que tiene un error, se obtendrá un mensaje como el siguiente:
{'rows': {'from': 1, 'to': 1}, 'type': 'error', 'record': 1, 'field': 'country_id',
'message': "No matching record found for external id 'base.ut' in field 'Country'",
'moreinfo': {'name': 'Possible Values', 'type': 'ir.actions.act_window', 'target': 'new', 'view_mode': 'tree,form',
'views': [(False, 'list'), (False, 'form')], 'context': {'create': False},
'help': 'See all possible values', 'res_model': 'ir.model.data', 'domain': [('model', '=', 'res.country')]}, 'field_name': 'Country'}
Aca podemos ver que se lista por registro (clave rows) que error hay. Lo mismo el campo y el mensaje de error. Esto permite listar a los usuarios los errores obtenidos durante el proceso de inserción/actualización. Este procesamiento de errores tiene su propia lógica que debe ser desarrollada, no es nada del otro mundo (si esperan que sea rápido y que aparte sea gratis y sencillo... sigan creyendo en Santa Claus). A diferencia del método convencional donde uno procesa los registros y va listando los errores a medida que los encuentra, con el método load primero se procesan todos los registros y luego se muestran los errores obtenidos.
Como actualizar campos many2many
El método load tambien puede actualizar campos many2many. Les doy un ejemplo. Debemos actualizar un contacto (que tiene el external/id a2_query_sales.REF0001) y asignarle la categoría Employees (con external/id base.res_partner_category_3). Para eso el valor de la variable fields y el formato de los datos es el siguiente:
fields = ['id','category_id/id']
data = ['a2_query_sales.REF0001','base.res_partner_category_3']
res = self.env['res.partner'].load(fields,[data])
Como utilizar el contexto
Un desarrollador de Odoo debe saber utilizar el contexto, es una herramienta fundamental. Sino hay cosas que no se pueden hacer (o no se entienden). Supongamos que necesitamos actualizar las facturas (modelo account.move). Para ello siempre tenemos que utilizar el contexto check_move_validity seteado en falso (en otro post explicamos porque). Ahora, si queremos actualizar el modelo account.move.line con el método load debemos hacerlo de la siguiente manera:
res = self.env['account.move.line'].with_context({'check_move_validity': False}).load(fields,[data])
Es interesante setear el contexto tracking_disable a True. Haciendo esto no se crean los mensajes de seguimiento de cambios en los registros. Esto puede llegar a acortar los tiempos del proceso de carga de datos en un 15%.
Como actualizar la metadata
Como dijimos antes, el método load es un método del ORM. Entonces Odoo al momento de actualizar los datos que se procesan con el método load hará los controles de seguridad pertinentes, chequeará los constraints definidos para dicho modelo y establecerá los valores default definidos en los modelos (entre otras cosas). Las funciones onchange no serán invocadas debido a que las mismas son invocadas por el cliente web.
Por eso el método load también automáticamente actualiza la metadata de Odoo (campos create_date, create_uid, write_date y write_uid). Y cuando se migra la información en Odoo debemos muchas veces actualizarla con la información original (por ejemplo, por motivos de auditoría). Es por ello que podemos utilizar el muy util módulo import_metadata de Thibault Francois. Este módulo nos permite actualizar la metadata durante la creación y escritura de registros. Es muy recomendable instalarlo previamente a una migración de datos.
Actualizando binary fields
Cada vez con más frecuencia necesitamos actualizar binary fields. Por ejemplo los attachments. En esto también el método load es muy rápido; probé crear 1,000 attachments para 1,000 ordenes de compra y lo hizo en menos de 15 segundos.
Para ello se tiene que actualizar el campo de tipo binary con el contenido del archivo convertido a base64. Por ejemplo; para cargar los attachments a las ordenes que tenía creada:
@api.model
def load_attachments(self):
fields = ['id','res_model','res_id','type','mimetype','datas','name','res_name']
orders = self.env['purchase.order'].search([])
data_lines = []
test_file = open('/tmp/stephen_king.png','rb')
data_file = base64.b64encode(test_file.read())
for order in orders:
data = [
'a2_query_sales.attachment_purchase_order_' + str(order.id),
'purchase.order',
order.id,
'binary',
'application/octet-stream',
data_file,
order.name,
order.name,
]
data_lines.append(data)
res = self.env['ir.attachment'].with_context({'tracking_disable': True}).load(fields,data_lines)
Lo que da el siguiente resultado: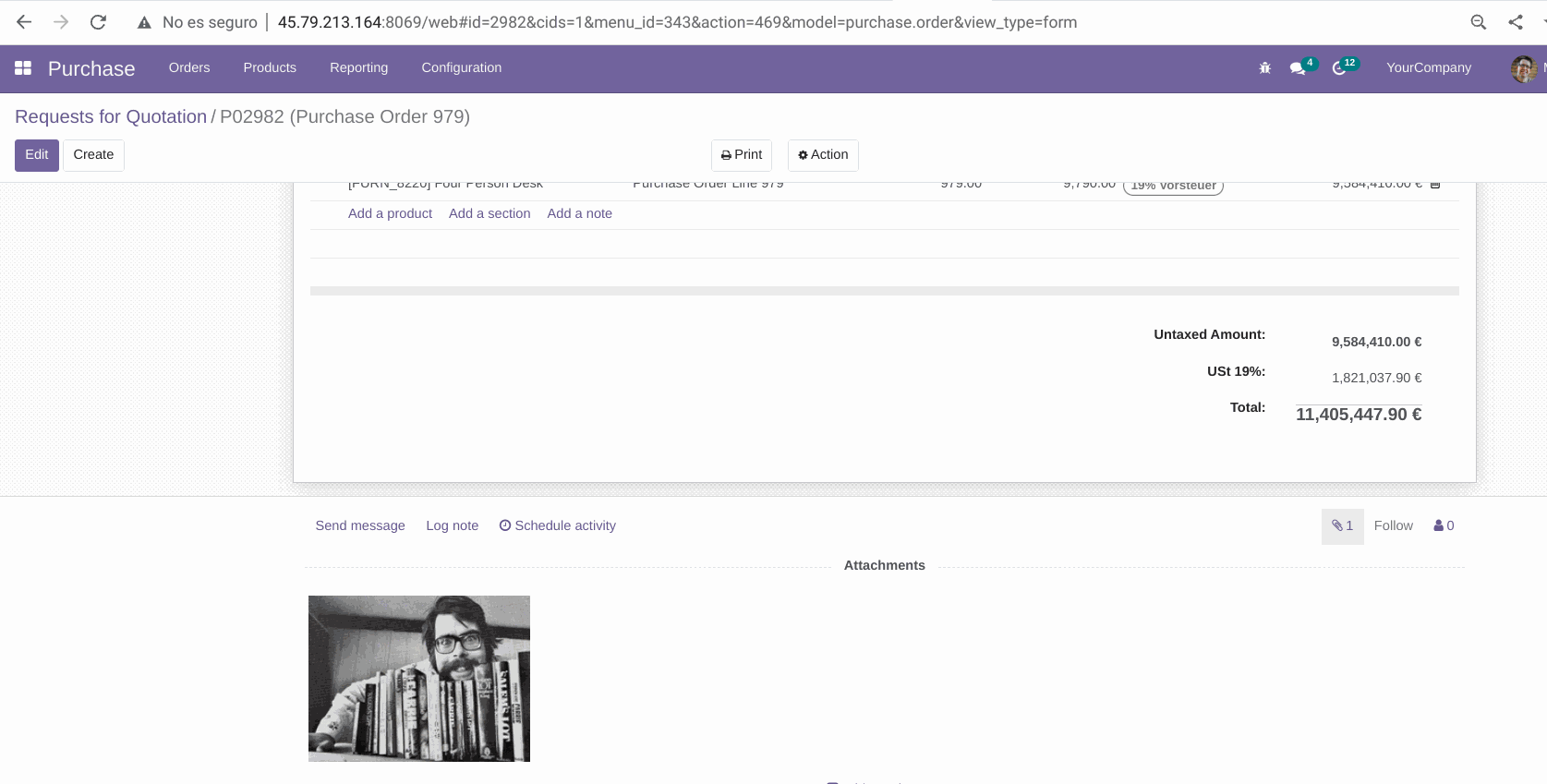
Conclusiones
No encuentro otro método más rápido que load para insertar y actualizar datos en Odoo. No solo inserta, sino tambien actualiza. Pero por sobre todo escalable. Es más rápido que hacer inserts y updates usando el ORM puro (por medio de los métodos write o create).
No hice benchmarks con el método COPY o con la sentencia INSERT/UPDATE de SQL, ahí el método es más lento. Pero lo bueno es que load hace uso del ORM. Lamentablemente es un método poco documentado, pero creo que cada desarrollador senior de Odoo debe conocer. Este método resuelve dos grandes limitaciones en las migraciones de datos. La primera es la velocidad de procesamiento y la actualización de los registros (esto no es menor, estamos hablando de migrar los datos en un día versus migrar los datos en una semana).
Estos son algunos tiempos despues de probar el método:
- cargar y actualizar 1000 contactos 32 segundos
- Crear y actualizar 1000 ordenes de compra: un minuto
- Insertar y actualizar 1000 líneas en las ordenes de compra: 30 segundos
- Importar 1,000 attachments con una imagen de 400Kb? 15 segundos.
Es por estos números que el método load merece ser tenido en cuenta.
Uno de los motivos por los cuales no se usa el método load y porque se lo considera complejo es su falta de documentación. El otro motivo es por el cual se lo usa poco es porque los datos deben ser transformados previos a su uso (por ejemplo, todos los registros referenciados en los campos de tipo many2one deben tener un external ID). Una vez que se comprende como hacerlo, es bastante sencillo de usar. Primero se necesita pre-procesar los datos y transformarlos previo a su carga. Pero eso es necesario en todos los contextos de nuestra industria. Como bien sabemos en todas las migraciones de datos se deben hacer tres pasos (el famoso ETL): Extracción, Transformación y Loading. Por lo pronto el método load resuelve los problemas de performance en la última etapa. Lo cual no es menor. De vuelta, estamos hablando de resolver la tarea en un día de procesamiento versus una semana (por ejemplo).
Por último, los procesos de migración de datos son dificiles. Por motivos de marketing se los muestra como trabajos sencillos, pero la verdad es que para llevar a cabo una migración exitosa se necesita mucho trabajo y conocimiento, y no va a ser facil. Por eso creo que los procesos de migración deben ser encarados con múltiples herramientas y en múltiples pasos. Si bien suena como una buena idea migrar con una sola herramienta apretando un solo botón, no es realista. No es practicable. Por eso una de las múltiples herramientas que debemos usar es el método load, el cual resuelve muchos problemas. Lamentablemente lo conozco muy tarde, me gustaría haberlo conocido años atrás y me hubiese ahorrado bastantes malasangres.