En la última semana estuvimos trabajando con la base de datos de un cliente que tenía decenas de usuarios concurrentes y un tamaño de 30 gigabytes (en Argentina nunca vi una base de datos de Odoo de ese tamaño.
Como siempre sostuvimos, la performance en Odoo es un tema en el que la mitad de las batallas se pelean en PostgreSQL; y en el caso de este cliente pasó lo mismo. La mitad de los problemas de performance estaban en PostgreSQL y la otra mitad los ocasionaba Odoo en PostgreSQL.
La importancia del VACUUM
VACUUM es un comando muy poderoso de PostgreSQL que hace varias cosas; entre ellas reclamara el espacio de la base de datos, recrear índices y (por sobre todo) actualizar las estadísticas de la base de datos (para que sean utilizadas por el optimizador basado en costos). VACUUM es quizá la herramienta más poderosa del arsenal del DBA de PostgreSQL. Conozco a dos DBAs experimentados en PostgreSQL que hicieron su experiencia trabajando décadas con temas de performance con Informix; y su comentario siempre fué "VACUUM resuelve muchísimos problemas"
Como ya deben saber; PostgreSQL es una base de datos que siempre crece en tamaño (por más que uno borre todos sus registros). Entonces para reclamar su espacio debemos eliminar físicamente aquellos registros que fueron borrados o actualizados; se ejecuta el VACUUM.
Nosotros en este cliente ejecutamos un VACUUM FULL durante horas de la madrugada, cuando los usuarios estaban off-line. Su ejecución duró minutos y se realizó sin problemas. La base de datos previa a la ejecución del VACUUM era de 30 gigabytes, post-vacuum pasó a ser de 15 gigabytes. Y los usuarios notaron un incremento en la performance de forma repentina.
Que se tiene que tener en cuenta del VACUUM? Ejecútelo una vez por semana. Si no sabe si se ejecuta, hágalo manualmente. No es el fin del mundo. Asegúrese de tener un backup solamente. Y hágalo cuando los usuarios estén off-line.
Cuando se hacen las cosas sin el ORM
Sabíamos que aún habían problemas de performance y un gran problema fue fácil de localizarlo debido a que hubo un momento que el server (dedicado) de la base de datos se detuvo y no hacía nada. Utilizando la herramienta pg_activity pudimos ver que solo se estába ejecutando una sentencia de SQL
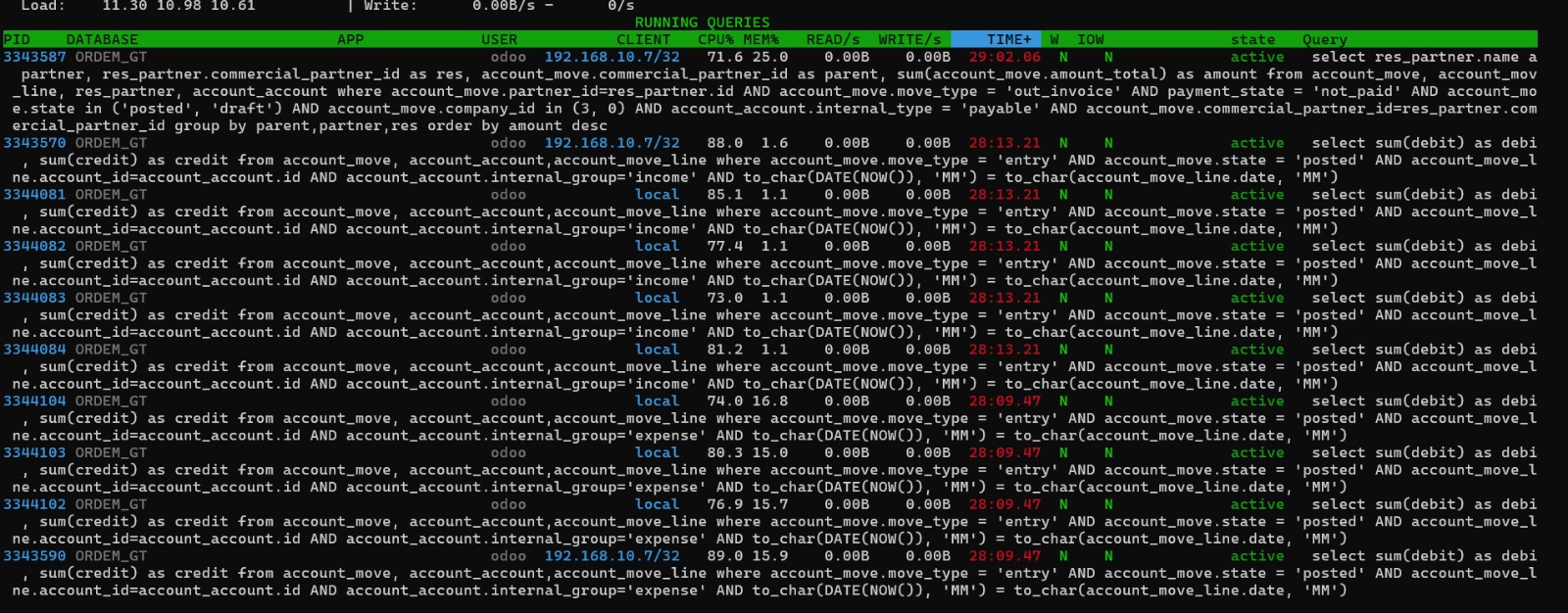
Definitivamente había una consulta que estaba consumiendo todos los recursos del servidor. Dicha consulta fue cancelada mediante el comando pg_terminate_backend en psql. Luego analizamos la consulta misma, ya que contábamos en el log con las consultas que duraban mucho tiempo. Y vimos que era la siguiente:
select sum(debit) as debit , sum(credit) as credit
from account_move, account_account,account_move_line
where account_move.move_type = 'entry'
AND account_move.state = 'posted'
AND account_move_line.account_id=account_account.id
AND account_account.internal_group='income'
AND to_char(DATE(NOW()), 'MM') = to_char(account_move_line.date, 'MM')
como pueden ver, no está especificado como hacer un join entre las tablas account_move y account_move_line (lo que ocasiona el producto cartesiano entre las mismas, lo que pone de rodillas al servidor de base de datos). Hicimos el explain y dió el siguiente resultado
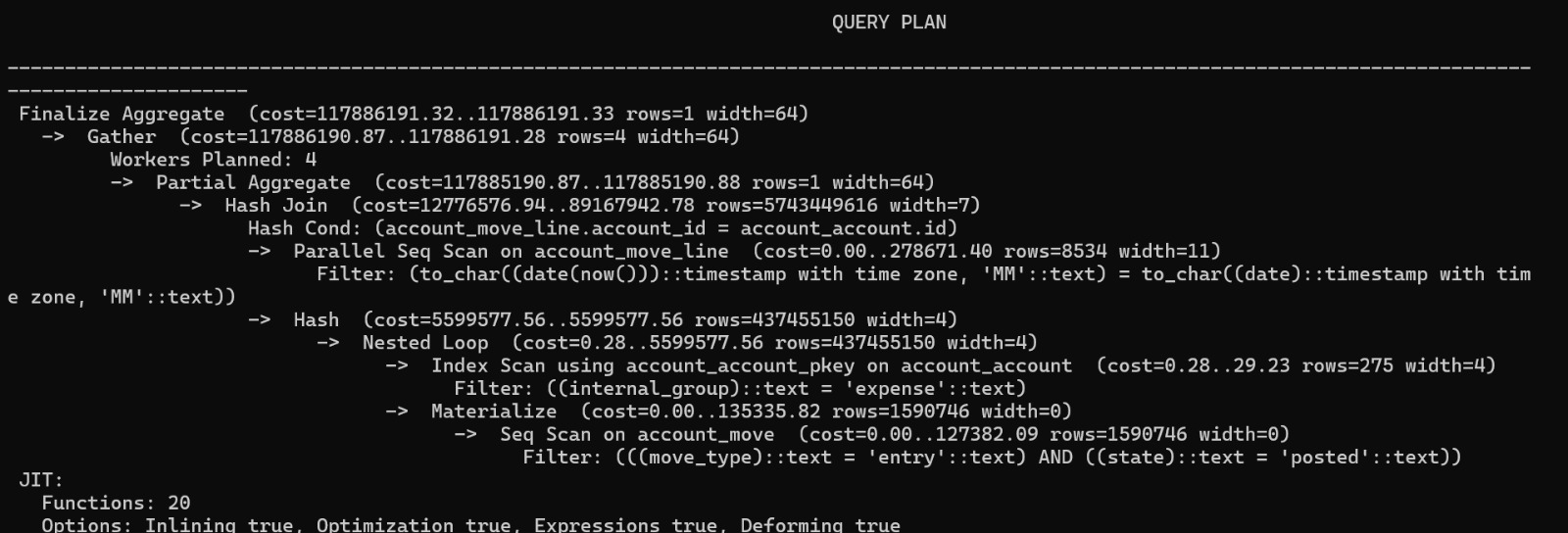
Como pueden ver, es carísimo en términos de recursos ejecutar este query. Luego probamos de reescribir el query con los joinsbien especificados
select sum(debit) as debit, sum(credit) as credit from account_move_line aml
inner join account_move am on aml.move_id = am.id
inner join account_account aa on aml.account_id = aa.id
where am.move_type = 'entry' AND am.state = 'posted' AND
aa.internal_group='expense'
AND to_char(DATE(NOW()), 'MM') = to_char(aml.date, 'MM');
Y al realizar el explain nos encontramos conque el costo de la consulta era significativamente menos caro en términos de recursos
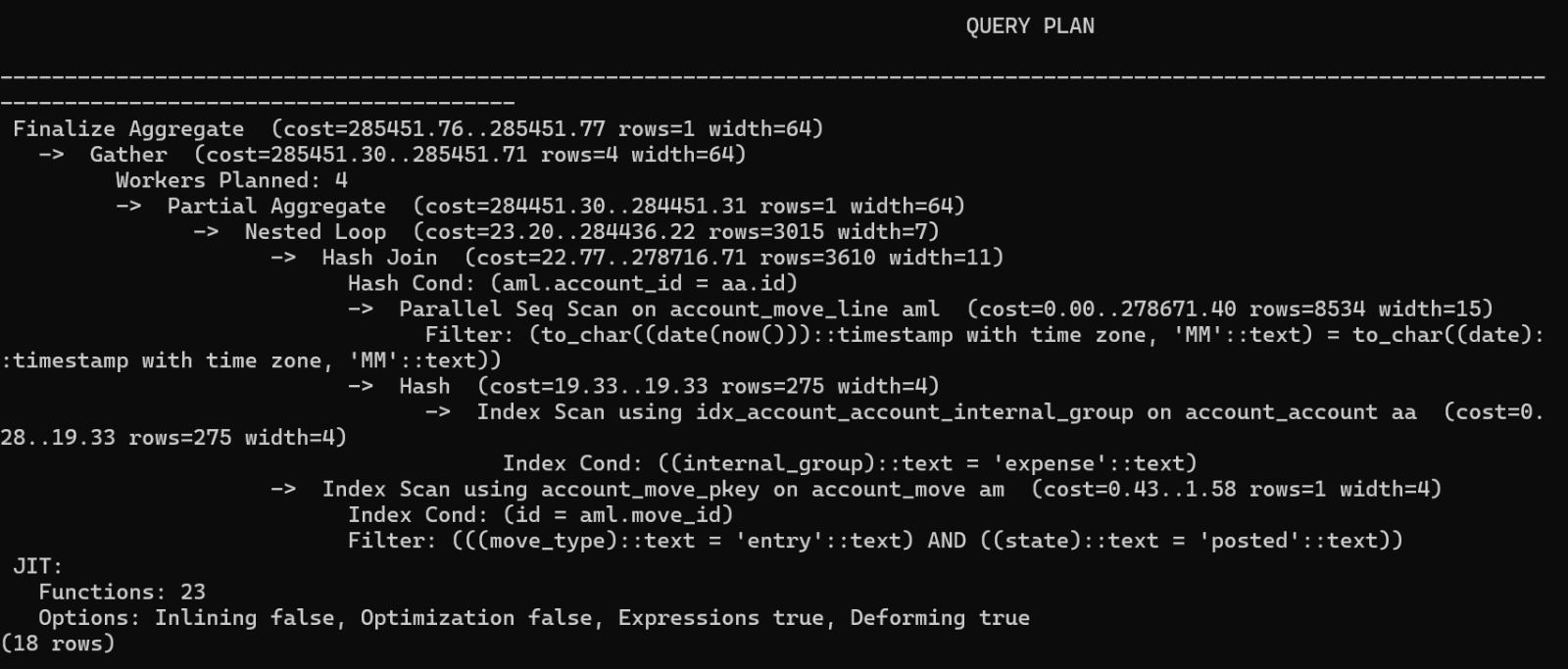
Que hicimos luego? Buscar en el código donde se construía la sentencia. Debido a que un error tan grosero en la sintaxis no es generado por el ORM, buscamos en los módulos custom donde se originaba la consulta y si, encontramos que la misma se realizaba salteando al ORM. Solo tuvimos que corregir ahí y se solucionó el problema.
Que aprendimos
Después de una semana de trabajo aprendimos varios temas, entre ellos
- Es importante realizar el VACUUM, ya sea manualmente o mediante el cron
- Uno debe contar con varias herramientas para detectar los problemas de performance. Puede ser pg_stat_statements, el log de PostgreSQL o pg_activity. No existe "la herramienta", sino el hacer uso juicioso de las mismas
- Usar la línea de comandos con PostgreSQL es importantísimo. Con PostgreSQL sucede lo mismo que con vi y los IDEs. Es importante dominar los conceptos fundamentales de performance de la base de datos. Un entorno de administración como el que brinda cualquier entorno cloud hace más fácil la vida. Pero eso no evita que uno deba conocer los fundamentos de performance de las consultas en la base de datos.
- Un DBA ayuda mucho, pero si el mismo no comprende como funcionan los módulos y el ORM de Odoo no va a llegar muy lejos.
- Por último, en instalaciones medianas o grandes no podemos dejar sola a PostgreSQL. Tarde o temprano vamos a tener problemas